hadoop环境搭建

hadoop环境搭建
Zero617第一章 hadoop环境搭建
第一节 虚拟机配置
1.1 安装Vmware软件
1.2 安装 Centos7 后修改虚拟机名称为 master
1.3网络连接配置
根据虚拟网络编辑器修改VMnet8的IP、网关和DNS。

1.4虚拟机网络配置
登录 CentOS 系统,进入 etc/sysconfig/network-scripts 中,编辑 NAT 网卡配置文件。修改为以下变量:
#修改 |

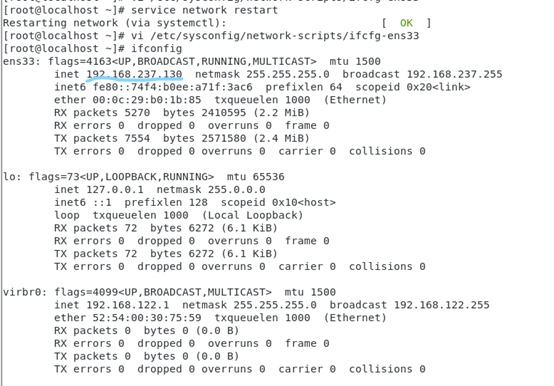
1.5重启网卡并检查IP是否变化。
ifconfig |
1.6关闭CentOS防火墙
关闭防火墙并禁止防火墙开机启动
systemctl stop firewalld.service #关闭防火墙 |

可以使用以下命令查看防火墙状态
systemctl status firewalld.service |

1.7使用fianlshell连接虚拟机继续操作
图形化界面和ftp工具便于操作。

PS:如果ssh连接报错,可以尝试执行sudo yum update。
第二节 基础环境配置
2.1 配置时钟同步
在线安装 ntpdate,使用阿里云 ntp 服务器同步时间,date 命令查看当前时间
yum install ntpdate |

2.2 配置主机名
在网络中能够唯一标识主机,和 ip 地址一样,可通过 ip 地址和网络主机名访问这台主机,作用:简化、方便。
hostnamectl set-hostname master #修改主机名为mastr |

2.3 配置hosts列表
hosts 列表作用是让集群中的每台服务器彼此都知道对方的主机名和 ip 地址,可以在这步时直接加入预计添加的从节点。

验证,ping ip 地址和主机名,结果相同无区别

2.5 Java安装
因为系统本身就有Java就没有去安装,但是后来发现无法使用jps命令。遂更新Java版本。
sudo yum install java-1.8.0-openjdk-devel.x86_64 |

可以用java -version验证Java版本。
2.6 Hadoop安装
使用 finalshell上传 hadoop 安装包至 /usr/hadoop文件夹下,解压 Hadoop 安装包。
tar -zxvf hadoop-2.10.1.tar.gz |
配置 Hadoop 环境变量
在配置文件最后添加以下两行
export HADOOP_HOME=/usr/hadoop/hadoop-2.10.0 |

将hadoop与java绑定
设置hadoop配置文件
cd /usr/hadoop/hadoop-2.10.0/etc/hadoop |
找到下面这行代码:
export JAVA_HOME=${JAVA_HOME} |
将这行代码修改为
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.312.b07-1.e179.x86_64/jre |

如果不知道 java 地址可以用 java -verbose 查找

使 hadoop 配置生效,并进行验证
source /etc/profile |
无错误信息表示hadoop已成功加入到CentOS系统环境中

第三节 配置Hadoop
3.1 Hadoop核心文件配置
进入 hadoop 的 etc 文件夹,配置 core-site.xml 文件,修改成以下内容
<configuration> |

配置 yarn-env.sh 文件,修改JAVA_HOME行为(记得去掉前面的注释符#):
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.312.b07-1.e179.x86_64/jre |

配置 hdfs-site.xml 文件,修改成以下内容:
<configuration> |

配置 mapred-site.xml 文件,通过 cp 命令生成不带后缀 template 的文件

编辑 mapred-site.xml 文件,修改为以下内容:
<configuration> |

配置 yarn-site.xml 文件
<configuration> |

修改 slaves 文件,删除原有内容,新增即将要建立的两个虚拟机的 hostname

3.2 克隆多台slave机
使用 master 镜像克隆 3 台虚拟机 (创建完整克隆),名称分别为 slave1、slave2、slave3,根据电脑配置情况可以自由设置数量,以下步骤与上方执行过程相同。
修改每个slave的主机名,方法同2.3
进入etc/sysconfig/network-scripts中,修改每台slave机的ip地址 ,方法同1.3
第四节 配置SSH登录
4.1 生成公钥私钥
在 master 和每台 slave 上,使用 rsa 算法产生公钥和私钥
4.2 发送公钥
在 master 上创建一个大家通用的公钥 authorized_keys,修改 authorized_keys 权限,并将这个公钥发送给每个 slave.
在master和每台slave上,使用rsa算法产生公钥和私钥(安装过程中,使用“Enter”键确定)
ssh-keygen -t rsa |
查看生成的私钥id_rsa和公钥id_rsa.pub
cd /root/.ssh/ |
在master上创建一个大家通用的公钥authorized_keys,修改authorized_keys权限,并将这个公钥发送给每个slave
cat id_rsa.pub >> authorized_keys |

4.3 验证SSH
ssh 登录检验,不需要密码即可登录路径从 ‘/.ssh ’ 变成 '’,登出为 exit

第五节 准备运行hadoop
5.1 格式化HDFS
在 master 机上,进入 hadoop 下的 bin 文件夹,运行以下代码:
hdfs namenode -format |
注意:只需格式化一次!多次格式化会导致 NameNode 和 DataNode 的集群 ID 值不匹配,需要在格式化前删除 NameNode,DataNode、日志等文件夹。
5.2 启动hadoop

5.3 jps检查进程

5.4 通过web端访问hadoop
查看 NameNode、DataNode:

查看 YARN 界面:









